A Markov reward process is defined by the tuple , where:
- is the state space
- is the state transition probability matrix
- is the reward function, where .
- is discount factor for future rewards.
MRP vs Markov chain
The only difference between an MRP and a Markov chain is that there is now a reward associated with each state, and the agent will select an action that will get the most reward at time .
The return for an MRP is the total discounted reward from time-step :
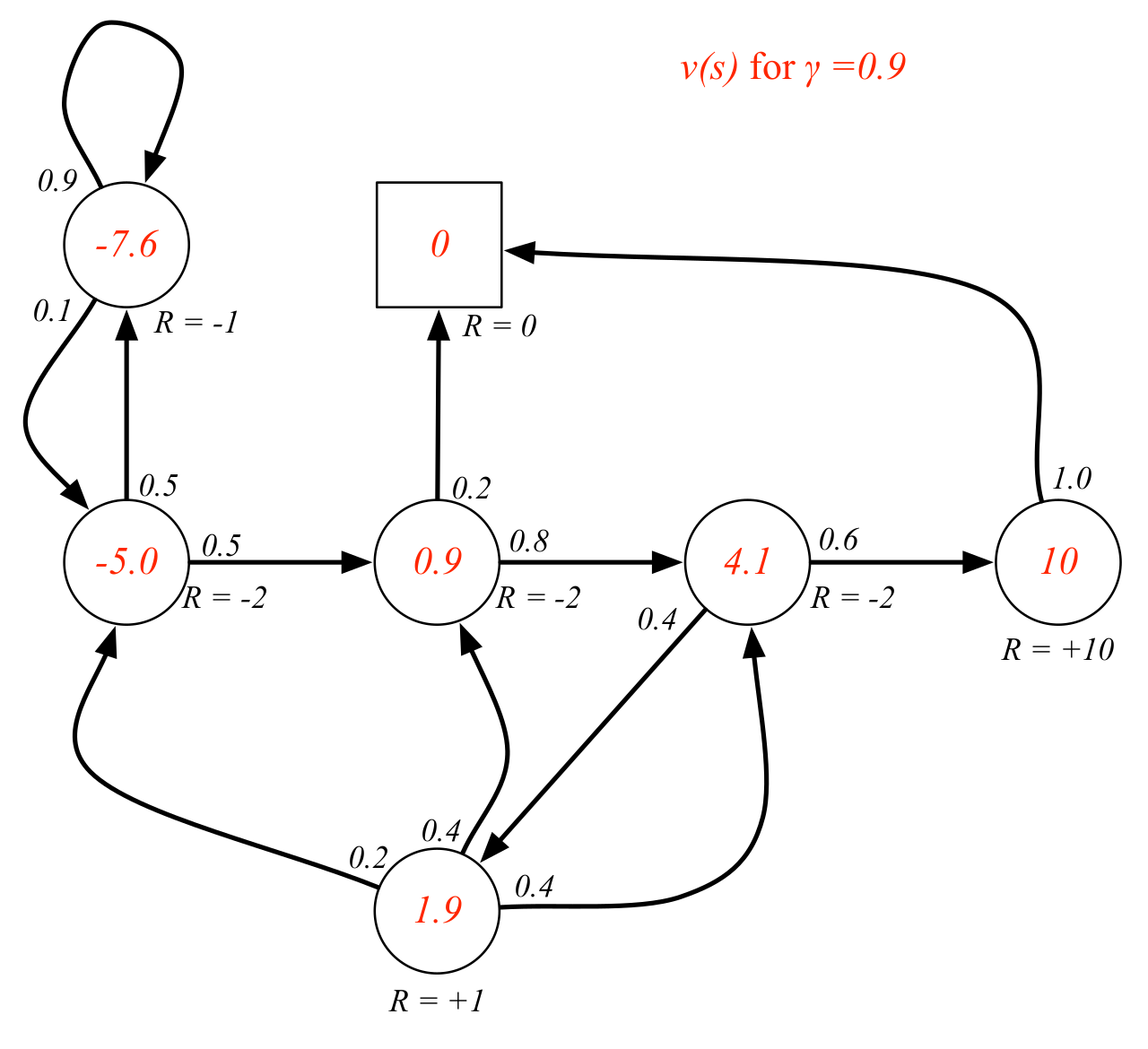
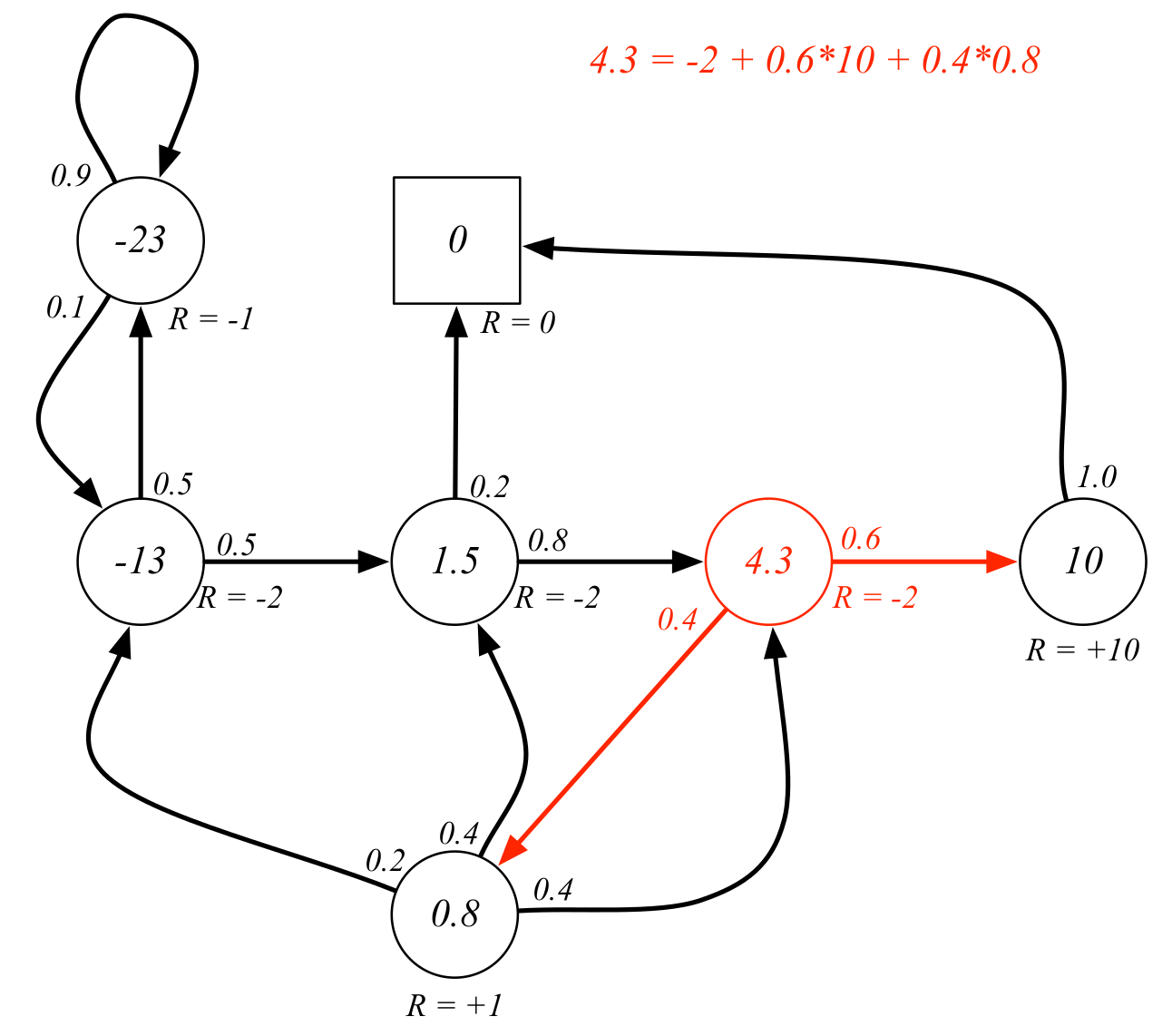
The state-value function for an MRP is defined as:
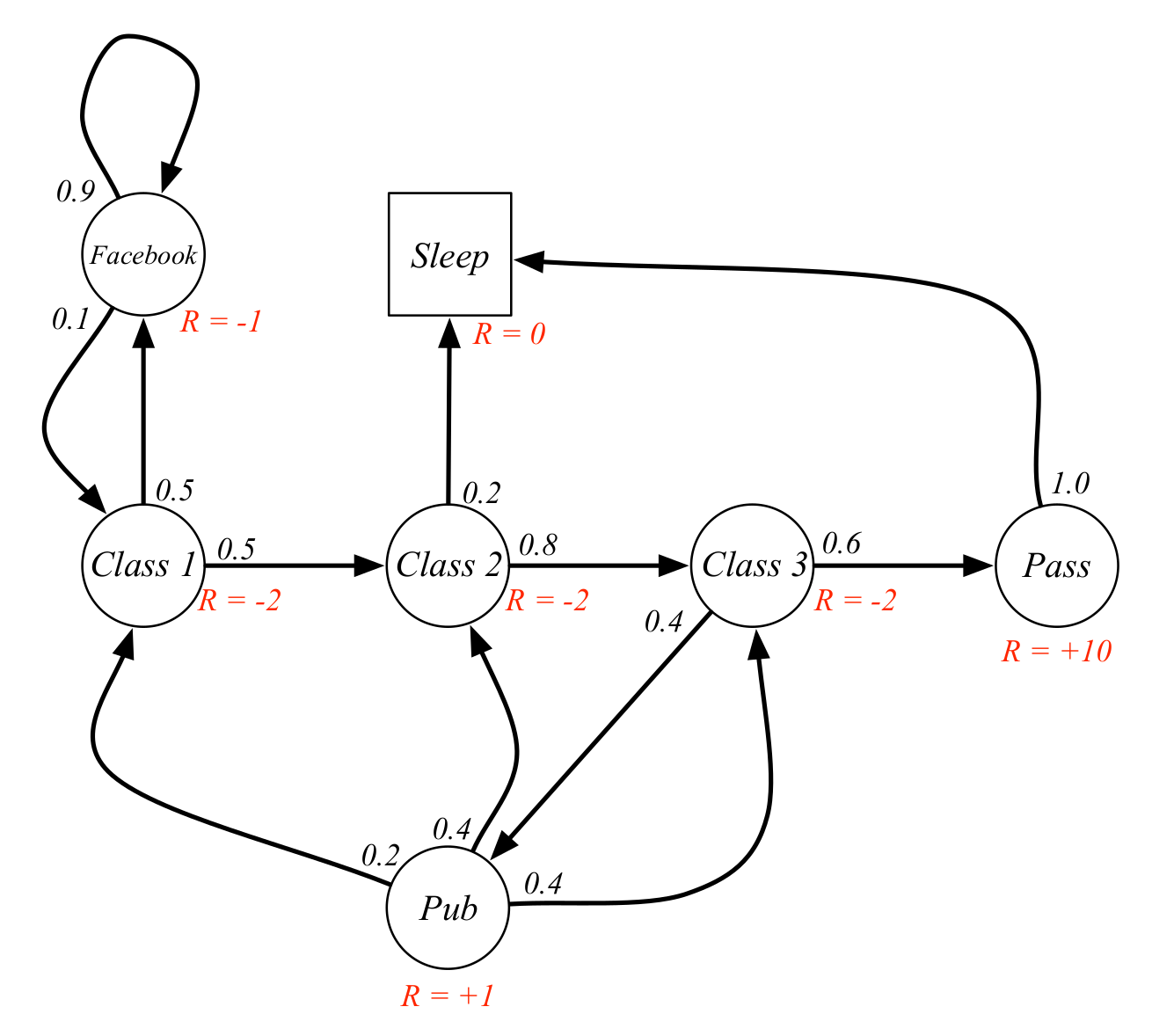
Example: A student's MRP