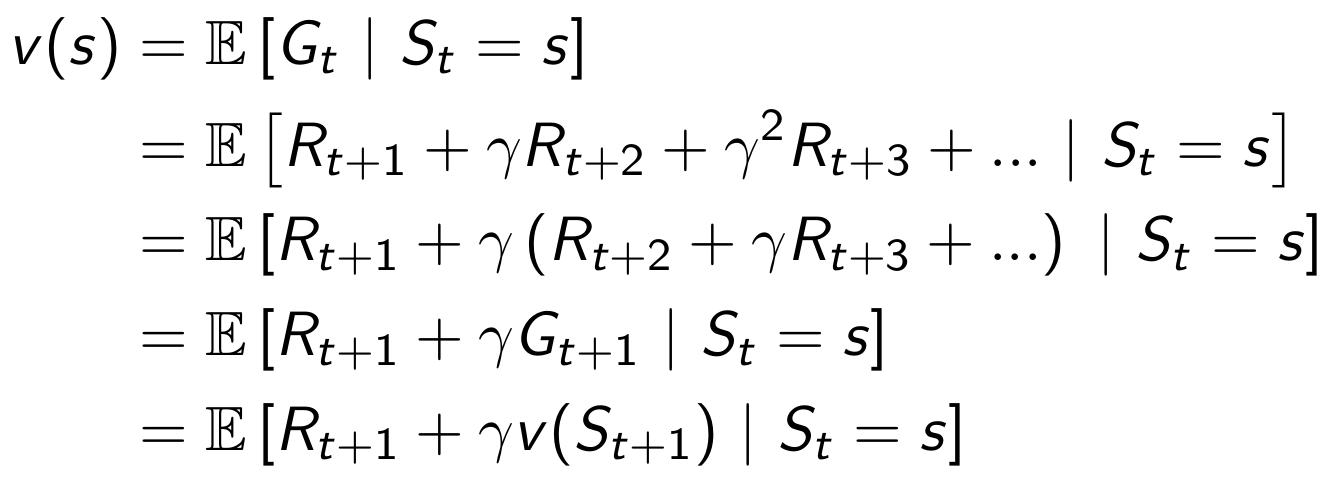The Bellman optimality equation provides a way to calculate a MRP’s optimal state-value function:
The value function works by doing a one-step look-ahead: we are given a recursive formula to calculate based on . The state value is the reward of current state plus the discounted and transition probability-weighted values of the next states (which we need to calculate in advance). Since we need to know the values of the next states, the calculation of the state value function must start at the final states (where it’s just ) and propagate the discounted final reward to the initial states.
In matrix form, the state-value function can be represented as:
To actually solve for the value function, we need to get a closed form formula by removing recursion :
Heavy computation
The time complexity of the calculation is , so this method is not very practical for large MRPs.
Derivation of equation
The equation can be derived by first decomposing into . We can recursively calculate the values by replacing the tail of the sum by the second term of the Bellman optimality equation.