A Markov decision process defined by the tuple is like a MRP but with actions/decisions:
- is the state space.
- is the action space (all the actions an agent can take).
- represents how likely it is for the agent to transition from state to by taking action .
- is the reward function. Note that we use (non-calligraphical font) to denote the reward actually received by the agent at time . The rewards should either be a measure of direct consequences of agent’s actions or it should be set to encourage the agent to take desired actions.
- is the discount factor for future rewards, representing how nearsighted the agent is.
To maximize total rewards, we need to solve for an optimal policy function to direct the actions of an agent in an MDP. See Bellman expectation equation for MDP value functions.
MDPs are super useful
We can formalize most RL problems as MDPs.
MDP vs Markov chain
A Markov decision process is different from a Markov chain in that the former allows an agent to make its own decision (instead of deciding randomly) and receive rewards from its decisions.
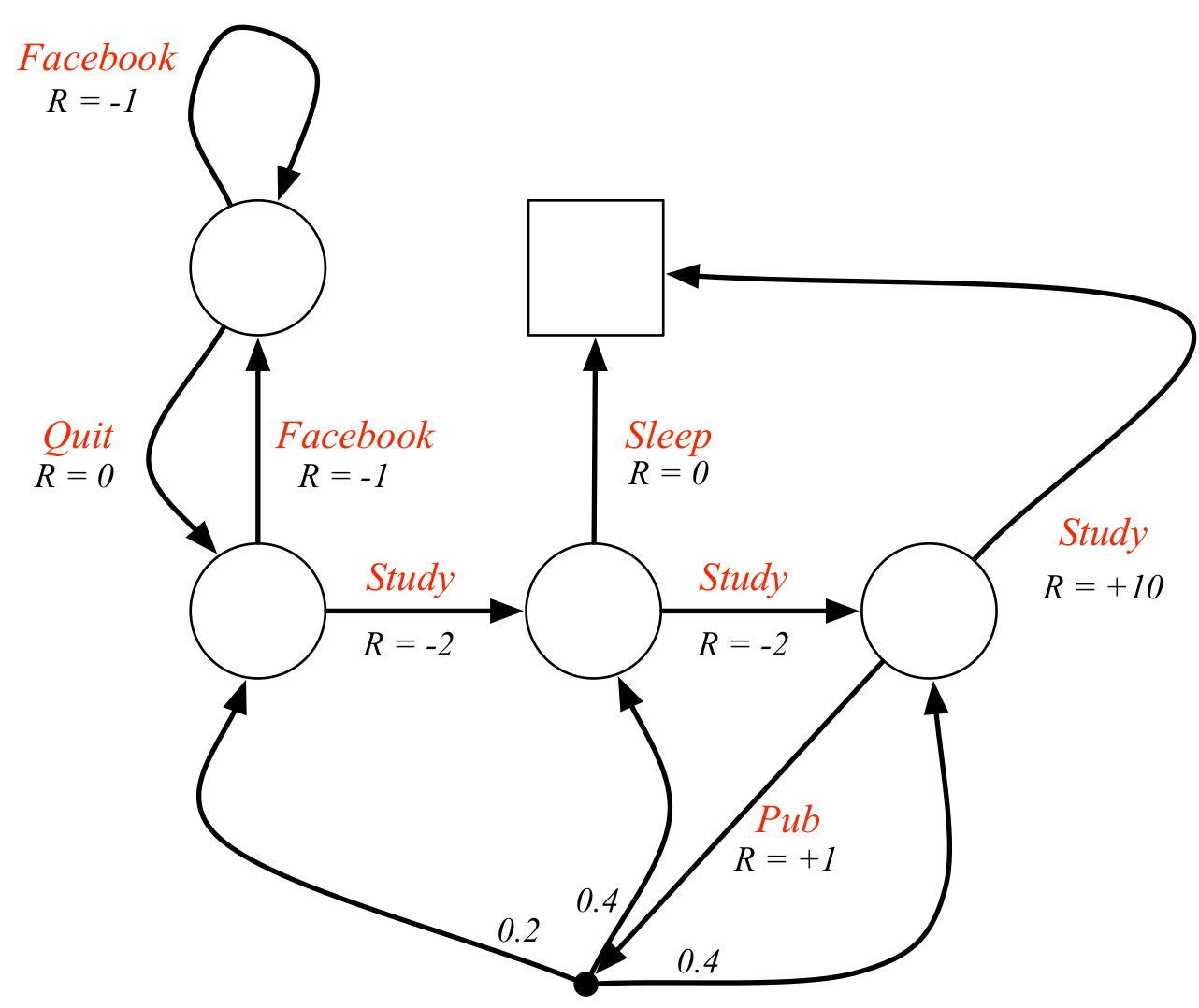
Student's MDP
A college student may behave like the following MDP: